Имитационные методы оценки мощности статистических тестов
При проверке статистических гипотез часто бывает недостаточно оценить риск ошибки первого рода α. Важно также определить вероятность β ошибки второго рода или мощность (1 - β) используемого теста при фиксированном уровне значимости αk и конкретных условиях и допущениях при проведении опыта. Научно обоснованное планирование исследований предполагает также построение функций мощности в зависимости от различных планов проведения эксперимента, в первую очередь, необходимого объема выборки и возможной величины тестируемого эффекта. Для реализации этого часто используют имитационные процедуры.
Анализ мощности с использованием имитаций предполагает выполнение следующих шагов:
1. Задаются предполагаемые параметры распределений случайных величин, наблюдение за которыми осуществляется в ходе эксперимента (средние, стандартные отклонения и др.).
2. Если оценивается мощность обнаружения эффекта с использованием статистической модели, то задаются также значения параметров этой модели (коэффициенты и отклонения для остатков).
3. Выбирается алгоритм проверки нулевой гипотезы относительно обнаруживаемого эффекта - это может быть любой статистический тест, математическое правило или коэффициент модели, значимость которых можно оценить, рассчитав
р-значение.
4. Алгоритм из п. 3 реализуется для произвольной случайной выборки из распределений с параметрами, заданными в п. 1.
5. П. 4 выполняется многократно (например, 10000 раз) и формируется вектор
р-значений.
6. Оценивается мощность обнаружения эффекта как доля р-значений от их общего числа, которые не превысили критическую величину α
k.
В сообщении рассматриваются варианты постронения имитационных процедур для анализа мощности различных тестов и моделей, куда вошли:
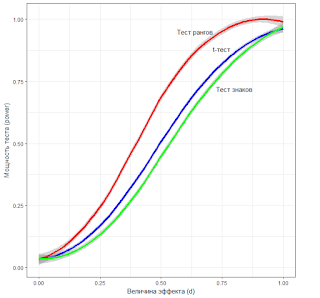
- параметрические и непараметрические тесты для оценки сдвига распределений;
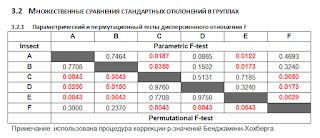
- модель однофакторного дисперсионного анализа;
- различные формы линейной регрессии с включением непрерывных независимых переменных и фиксированных факторов;
- модели со смешанными параметрами (с использованием пакета simr).