Экологические ниши, их современная интерпретация и моделирование с использованием пакета ecospat
 Экологическая ниша - термин, пользующийся странной популярностью: многие употребляют, но немногие задумываются над его смыслом. Чем отличается ниша Гринелла от ниши Элтона? Стоит ли рассуждать о реализованных нишах, если примеры их построения практически неизвестны? В этом сообщении мы делаем достаточно подробный обзор статей Дж. Соберона (Soberon) и А. Петерсона (Peterson), последовательно пытающихся разобраться в этих непростых вопросах (правда на уровне простеньких картинок, иллюстрирующих пересечения неких умозрительных множеств).
Экологическая ниша - термин, пользующийся странной популярностью: многие употребляют, но немногие задумываются над его смыслом. Чем отличается ниша Гринелла от ниши Элтона? Стоит ли рассуждать о реализованных нишах, если примеры их построения практически неизвестны? В этом сообщении мы делаем достаточно подробный обзор статей Дж. Соберона (Soberon) и А. Петерсона (Peterson), последовательно пытающихся разобраться в этих непростых вопросах (правда на уровне простеньких картинок, иллюстрирующих пересечения неких умозрительных множеств). Но для тех, кому захочется самому построить гринеллевскую фундаментальную нишу, мы рекомендуем обратить внимание на R-пакет ecospat. Сразу оговоримся, что многое в этом пакете не понравилось. Раздел "предварительного анализа данных" вроде бы содержит полезные функции разведывательных операций, но напоминает "окрошечную смесь" из пространственной автоковариации, филогенетических индексов, оценок сопряженности встречаемости видов, сходства географических пространств и чего-то еще маловменяемого. Все делалось как-то впопыхах и лучше для выполнения этих расчетов обращаться к специализированным пакетам. Раздел, посвященный моделям коллективного прогнозирования, может оказаться полезным (наряду с пакетом ForecastCombinations и многими другими на ту же тему) именно в случае географического прогнозирования. Но при выполнении вычислений выводится большое количество мало нужной информации, тогда как ко многим ключевым показателям добраться не всегда удобно. Раздел, посвященный пространственно-обусловленному моделированию совокупности видов (SESAM) также оказывает несколько отстраненное впечатление.
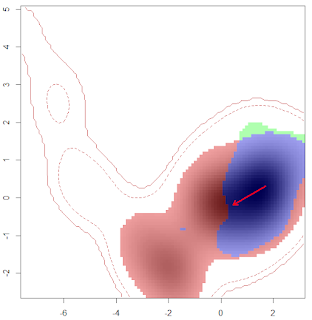
При всем этом, функции построения пространства ниш и оценки их перекрытия выполнены на весьма приличном уровне. Пакет R-функций ecospat (Broennimann et al., 2012; Di Cola et al., 2017) дает возможность построить произвольно сглаженную поверхность индекса экологической пригодности в осях двух главных компонент, основываясь на традиционной таблице «местообитания – переменные среды», что позволяет учесть полный набор факторов. Это - важный момент, поскольку в известных пакетах virtualspecies, dismo и др., ортогональное пространство наименьшей вариации (РС) формируется на основе растров геоклиматической информации, представленной в ячейках ("пикселах") равномерной сетки географических координат высокого разрешения. Представить в такой форме локальные характеристики речных биотопов, такие как состав химических ингредиентов, гидрологические параметры водотока, тип донного грунта и т.д., традиционно ключевые для гидробиологии, представляется невозможным.
В нашем сообщении мы подробно рассматриваем функции построения и перекрытия одномерных и двумерных ниш на собственном примере - гидробиологической съемке донных сообществ в малых реках бассейна Средней и Нижней Волги.
Текст сообщения в формате PDF может быть загружен с ресурса
http://www.ievbras.ru/ecostat/Kiril/R/Blog/23_Niche.pdf
Исходные данные, обрабатываемые с помошью скриптов, представленных в сообщении можно скачать с http://www.ievbras.ru/ecostat/Kiril/R/Blog/WB_niche.RData .