Рассматриваются проблемы форвардного прогнозирования значений бинарных временных рядов (binary time series predicting). В качестве рабочего примера использовался фрагмент базы данных о частоте посещений одним из покупателей в течение трех лет магазинов популярной российской кампании (может быть загружен с ресурса
http://www.ievbras.ru/ecostat/Kiril/R/Blog/POS10x.RData ) .
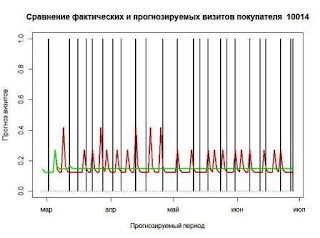
Ставилась задача предсказания дат наиболее вероятных визитов в течение некоторого тестируемого периода. Наилучшее решение искалось с использованием трех основных концепций построения моделей временных рядов:
1. В классе обобщенных моделей, использующих пространства состояний (Generalized State Space Modeling) . С помощью функций пакета glarma (Generalized Linear AutoRegressive Moving Average) выполнялось построение линейных моделей авторегрессии - скользящего среднего для дискретной случайной величины, имеющей Бернулли, биномиальное, Пуассона или отрицательное биномиальное распределение. Другой вариант моделей того же бинарного временного ряда был получен с использованием пакета tscount.
1. В классе обобщенных моделей, использующих пространства состояний (Generalized State Space Modeling) . С помощью функций пакета glarma (Generalized Linear AutoRegressive Moving Average) выполнялось построение линейных моделей авторегрессии - скользящего среднего для дискретной случайной величины, имеющей Бернулли, биномиальное, Пуассона или отрицательное биномиальное распределение. Другой вариант моделей того же бинарного временного ряда был получен с использованием пакета tscount.
2. На основе байесовской структурной модели временных рядов (Bayesian structural time series). Расчеты выполнялись с использованием функций, реализованных в пакете bsts.
3. С использованием однородных марковских цепей дискретного временного ряда. Классический подход к моделированию марковских процессов (без какого-либо ощутимого успеха) был апробирован на основе пакета markovchain. Значительно более впечатляющие результаты прогнозирования были получены при использовании другого пакета depmixS4, который реализует в среде программирования R общие принципы формирования стандартных и скрытых моделей марковских цепей.
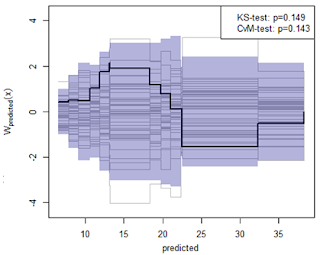
Результаты тестов на форвардное прогнозирование временного ряда, полученные вышеперечисленными пятью пакетами, сравнивались с простейшим способом предсказания на основе оценок вероятностной плотности распределения событий.
С методической точки зрения при могут быть интересны некоторые приемы обработки исходных данных на основе библиотеки "tidy data" Х.Викхэма
С методической точки зрения при могут быть интересны некоторые приемы обработки исходных данных на основе библиотеки "tidy data" Х.Викхэма
Текст сообщения в формате PDF может быть загружен с ресурса
http://www.ievbras.ru/ecostat/Kiril/R/Blog/13_BTS.pdf